Веб в кэшах
В современных веб-приложениях постоянно используется кэширование. Это касается как проектов, разрабатываемых «с нуля» большими командами, так и сайтов, основанных на коробочных CMS. В первом случае возможно до введения дополнительной прослойки пересмотреть медленный участок кода и заняться оптимизацией (ну, так у крутых ребят происходит, надеюсь). В случае же с CMS картина сильно разнится — клиенты не всегда согласны на длительные исследования и тесты. «Ускорьте сайт. Вот, я нагуглил такой способ» — говорят они. И никакие доводы уже не принимаются. У Васи в интернете же сработало. Но, это совсем другая история. А я здесь всё же о кэшировании.
Если попытаться упрощённо обобщить процесс, происходящий до того момента вывода страницы в браузере, то можно выделить несколько обязательных шагов:
- Веб-сервер должен корректно работать (мы здесь не оффлайн версии рассматриваем)
- Обработка запроса
- Получение данных из СУБД
- Формирование документа
- Загрузка документа браузером
- Загрузить статику (css, js, картинки и т.п.)
Так же, думаю, введём разные типы кэша:
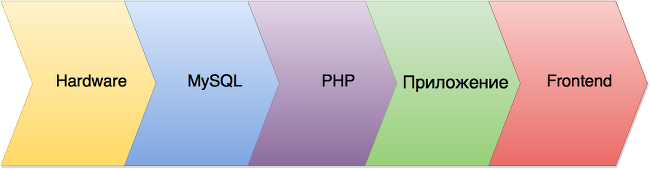
- Hardware (HDD, процессор)
- Кэш запросов MySQL
- Кэш в PHP
- Кэш приложения
- Frontend
Hardware
Этот тип относится к работе приложения опосредованно, через обеспечение быстродействия самого сервера.
Про отличия архитектуры серверных и персональных компьютеров уже написано достаточно много. Остановимся на трёх особенностях: многоуровневый кэш процессора (L1, L2, L3), дисковый кэш и страничный кэш (page cache).
Большинство современных микропроцессоров для компьютеров и серверов имеют как минимум три независимых кэша: кэш инструкций для ускорения загрузки машинного кода, кэш данных для ускорения чтения и записи данных и буфер ассоциативной трансляции (TLB) для ускорения трансляции виртуальных (логических) адресов в физические, как для инструкций, так и для данных. Кэш данных часто реализуется в виде многоуровневого кэша (L1, L2, L3).
Процессор обрабатывает данные из оперативной памяти. Но скорость работы процессора значительно выше, чем у ОЗУ. Если бы процессор напрямую обращался к памяти (чтение и запись), то большую часть времени простаивал. Именно для нивелирования задержек доступа к данным в оперативной памяти и используется кэш-память, работающую быстрее, чем оперативная. Причём, даже если на основе SRAM создать оперативную память, не уступающую по скорости работы процессору, всё равно потребовалось бы некое временное хранилище для считываемых или записываемых блоков данных. Подобный кэш, конечно же, был бы устроен иначе и имел бы совсем другой размер.

Различают кэш-память трёх уровней (L1, L2 и L3).
L1 самый быстрый, но и самый маленький по объёму. С ним напрямую работает ядро процессора. Кэш-память первого уровня имеет наименьшее время доступа.
Объём памяти L2 значительно больше, чем L1. Но и время поиска хранящихся данных возрастает.
Третий уровень обладает наибольшим размером памяти и значительно медленней первых двух. Если данные не обрабатывались или процессор должен обработать срочные данные, то для освобождения кэш-памяти второго уровня данные перемещаются в память третьего уровня.
Размеры L1/L2/L3 кэшей у серверных процессоров значительно больше, чем у моделей для персонального использования.
Подобно кэш-памяти процессора, дисковый кэш помогает сгладить различия в скорости чтения-записи и передачи данных.
При выполнении чтения с диска считывающая головка постепенно добирается до трека с запрошенными данными и через небольшой промежуток времени начинает считывать биты. Как правило, обычно считывается немного больше данных, чем было запрошено. Встроенный буфер жёсткого диска сохраняет этот излишек, на случай если операционная система запросит эти данные позже.
Во время сохранения файла данные не сразу записываются на диск. Первоначально заполняется дисковый кэш и система получает сигнал, что операция записи завершена и можно продолжать работу. Магнитная головка в это время всё ещё занята записью. Если во время процесса записи обесточить компьютер, то данные из буфера потеряются и возможны появления ошибок в файловой системе. Энергонезависимые RAID-контроллеры решают эту проблему.
И всё равно дисковые операции очень медленные. Доступ к данным в памяти выполняется значительно быстрее, чем к данным на диске. Так же, если к некоторым данным осуществлялся доступ, то с достаточно большой вероятностью к этим же данным в ближайшем будущем потребуется обратиться снова (библиотека может использоваться несколькими процессами).
Здесь на помощь приходит страничный кэш. Его предназначение — минимизировать количество дисковых операций ввода-вывода путем хранения в памяти тех данных, для обращения к которым необходимо выполнять дисковые операции.
Страничный кэш состоит из физических страниц, которые находятся в оперативной памяти. Каждая страница памяти в кэше соответствует нескольким дисковым блокам. Когда ядро начинает некоторую операцию страничного ввода-вывода (дисковые, обычно файловые, операции ввода-вывода, которые выполняются порциями, равными размеру страницы памяти), то оно вначале проверяет, нет ли соответствующих данных в страничном кэше. Если эти данные существуют, то ядро может не обращаться к диску и использовать их прямо из страничного кэша. Отдельные дисковые блоки также могут быть привязаны к страничному кэшу с помощью буферов блочного ввода-вывода.
Кэш запросов MySQL
Как бы сильно мы не оптимизировали код нашего приложения, все усилия может свести на нет база данных.
MySQL предоставляет удобный инструмент кэширования запросов. Причём, кэшируется не план выполнения, а непосредственно результат.
Query Cache работает с запросами, начинающимися с «SEL», т.е. select запросы можно кэшировать в общее для разных сессий пространства памяти. Что позволяет выполнять повторяющиеся запросы быстрее.
MySQL в качестве ключа для хранения запроса использует хэш, поэтому очень важно писать в одном стиле. Например,
SELECT `field` FROM `table`;
и
select `field` from `table`;
рассматриваются как два разных запроса и никакого выйгрыша в скорости мы не получим.
Кроме самого результата запроса, MySQL сохраняет в кэш список таблиц, из которых делались выборки. Как только такая таблица изменяется, все связанные с ней выборки удаляются из кэша. Лучше всего кэш запросов подходит для редко обновляющихся таблиц.
Query Cache не работает с рядом стандартных функций. А так же с запросами, содержащими пользовательские функции, хранимые процедуры, выборки из баз mysql, INFORMATION_SCHEMA и performance_schema.
На ряду с кэшем запросов стоит обратить внимание на InnoDB Buffer Pool
Что нам может дать PHP?
Интерпретатор PHP при каждом вызове скрипта обращается к соответствующему файлу, генерирует байткод и выполняет его. Весь этот процесс занимает время.
При поиске требуемых файлов и директорий PHP обращается к файловой системе. Для пары файлов такие запросы кажутся мгновенными, но в большом приложении подобный поиск занимает уже ощутимое время. Использование realpath cache (параметры realpath_cache_size и realpath_cache_ttl) позволяет сократить время повторного вызова файла.
Для ускорения генерации байткода используются специальные модули — акселераторы (Opcode cachers). При первом вызове скрипта опкод сохраняется в памяти или на диске. Следующие обращения к скрипту используют уже хранящийся в кэше код, и повторная интерпретация не происходит.
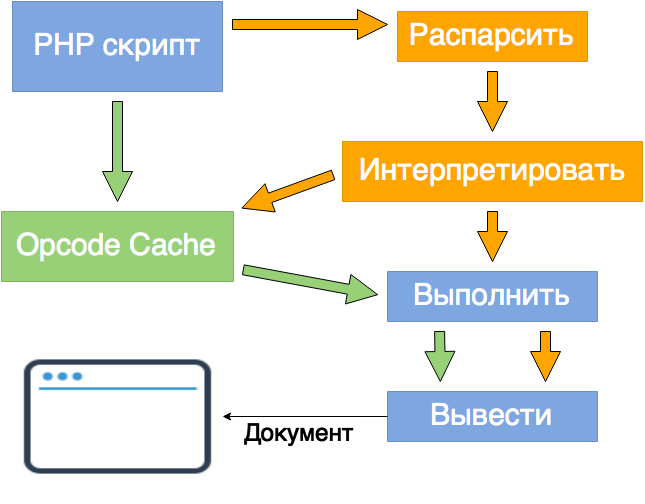
Наиболее популярные акселераторы — APC (поддержка завершилась на версии PHP 5.4), eAccelerator (также только до 5.4), XCache и Zend OPcache (начиная с PHP 5.5).
Кэш приложения
Что же делать, когда администратор уже выжал всё что мог из настроек сервера, а приложение всё равно работает достаточно медленно? Оптимизировать код же!
И, пока другие заняты рефакторингом, мы будем кэшировать.
Для чего же и как мы можем использовать кэш? Любые данные, меняющиеся достаточно редко или требующие долгих вычислений, можно поместить в отдельное хранилище. Так, массив можно сериализовать и сохранить в файл или сложить в быстрое хранилище, работающее с памятью сервера (memcached, redis).
Главное не переусердствовать. Нельзя забывать что кэш — это не база данных. Данные в нём могут храниться долго, но всё равно, обычно, не постоянны. И приложение не должно полагаться только на наличие чего-то в кэше. Всегда существует ветвление «есть данные — берём из кэша; нет — получаем, используем и сохраняем в кэш». Да и память имеет свойство заканчиваться. Механизм инвалидации кэша так же ложится на плечи авторов приложения.
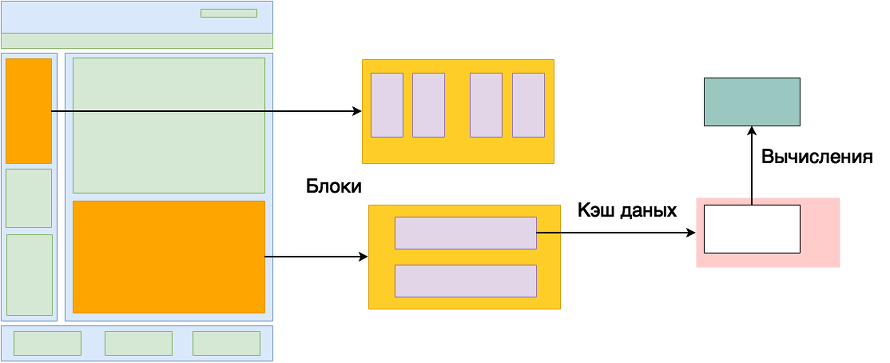
Если рассмотреть генерацию страницы, то можно выделить несколько вариантов кэша.
Данные для вычислений — если в пределах одного запроса результат вычислений требуется в нескольких местах, а при следующем запросе данные устаревают, то есть смысл создать хранилище внутри объекта. Заполнив это хранилище при первом вызове, использовать хранящиеся там данные в последующие разы. Схожую цель носит паттерн Registry.
Данные для рендера — просто набор данных из быстрого хранилища, необходимые для формирования блоков.
Блоки — статические или редко меняющиеся части страницы, уже заполненные данными и представляющие собой код, готовый для вывода на странице.
Полностраничный кэш — сохраняется полностью готовая для вывода страница со всеми блоками и данными. Этот вариант предпочтительней всего с точки зрения производительности, так как полный процесс генерации страница происходит только один раз. Опять же, получаем ветвление «запрошенная страница уже сохранена — отдаём и завершаем запрос, нет — генерируем, сохраняем, отдаём». Причём, не обязательно дожидаться вызова страницы пользователем, вполне возможно реализовать инструмент генерации подобных страниц из админки. В итоге, получаем набор полностью готовых для вывода страниц, не требующих дополнительных запросов и вычислений. Инвалидация, конечно, тоже на совести разработчика.
Но, к сожалении, не всё так просто с полностраничным кэшем. Во времена статичных HTML-страниц всё было хорошо, и каждый сайт представлял собой такой набор готовых отвёрстаных страниц. Сейчас же, для каждого пользователя необходимо вывести совершенно уникальную для него информацию (имя, залогинен или нет, количество товаров в корзине, друзья онлайн и т.п.). Можно не пытаться сгенерировать все возможные варианты страницы даже для одного пользователя.
В таком случае применяют комбинированный подход — если посмотреть на страницу, то основная информация для всех пользователей одна и та же. Отличаются именно дополнительные детали. Ничто не мешает сохранить весь повторяющийся костяк страницы, вместе с основным контентом, а динамические (авторизация, просмотренные товары, приветствие и т.д.) генерировать уже на основании сессии пользователя. Эта генерация может проходить как во время обработки запроса (FPC не сразу отдаёт клиенту страницу, а вызывает недостающие обработчики для заполнения динамических блоков), так и после загрузки страниц (например, при использовании Varnish страница без динамических блоков загружается сразу, а дополнительную информацию подгружают отдельным AJAX-запросом). Опять же, при генерации динамики свободно можно использовать более мелкие типы кэша.
Frontend
Именно на оптимизации фронтенда заказчики нарываются в поиске чаще всего. PageSpeed Insights и YSlow — наиболее простые и понятные инструменты. Да и рекомендации дают ясные — здесь подкрути, там добавь и будет счастье. А то что страница у нас грузится больше минуты — так гугль об этом вскользь упоминает.
На эту тему статей написано уже более чем достаточно. Заголовки Cache-Control, Last-Modified, If-Modified-Since, Expires разобраны в десяках статей с доступными примерами и пояснениями. Добавить уже практически нечего. Общий принцип прост:
— запрошенный файл (страница, css, js, etc.) уже загружался и сохранён? Не надо загружать снова.
— Что-то новенькое? Давай-ка его сюда.
Некоторые разработчики так же используют для хранения части документа локальное хранилище браузера (local storage). Здесь стоит рассматривать каждый случай отдельно, готового рецепта не существует.
Но не всегда браузер запрашивает данные напрямую с оригинального сервера.

На пути запроса может стоять кэширующий прокси-сервер, сохраняющий файлы многих клиентов сразу. К сожалению, полноценно работают только с протоколом HTTP (при HTTPS соединении сохранение каких бы то ни было данных компрометирует саму идею SSL-шифрования).
Сервис Flipboard в описании своего робота так и пишет:
Flipboard uses a proxy service to fetch, validate, and prepare certain elements of websites for presentation through the Flipboard Application.
As an administrator, you may notice the «Flipboard» or «FlipboardProxy» user agents in your logs recording a cluster of relatively tightly spaced requests. These requests generally come in response to a user request that our service scan a social media feed (Twitter, for example) and construct a processed feed of items to deliver in real time. Our requests currently all originate from the Amazon EC2 cluster.
Кроме кэширующего сервера существует ещё и реверсивный (обратный) прокси сервер (reverse proxy). Его задача — принять запрос и предоставить ответ как можно быстрее. Реализаций достаточно много, но в нашем случае основные — это балансировщик нагрузки и CDN.
А вообще, протокол SPDY, а за ним и HTTP/2 должны внести большие изменения в принципы фронтенд оптимизации. Поживём — увидим.
Вот, собственно, и всё. Это, конечно, не полный список, но я и не задавался целью написать подробный справочник. Идею, что кэширование применяется везде и не стоит бояться его использовать, думаю, донёс. Только без фанатизма — сначала исправляем узкие места, а потом кэшируем. Не наоборот :-)